Formale Sprachen sind künstliche Sprachen, die es Computern ermöglichen, Daten und Informationen zu verarbeiten. Eine formale Sprache L besteht aus einer Menge von Wörtern, die wiederum aus Zeichen des Alphabets ∑ der Sprache bestehen.
Das Alphabet ist hierbei die Menge der Zeichen, die in einem Wort benutzt werden dürfen, wie zum Beispiel die Buchstaben von A bis Z und Umlaute im deutschen Alphabet.
Formale Sprachen werden durch Grammatiken erzeugt.
Zu diesem Thema finden sich viele gute Einführungen u.a. sei hier die sehr informative Seite von Studyflix E-Learning empfohlen (www.studyflix.de), auf deren Inhalte hier stellenweise Bezug genommen wird.
Grammatiken
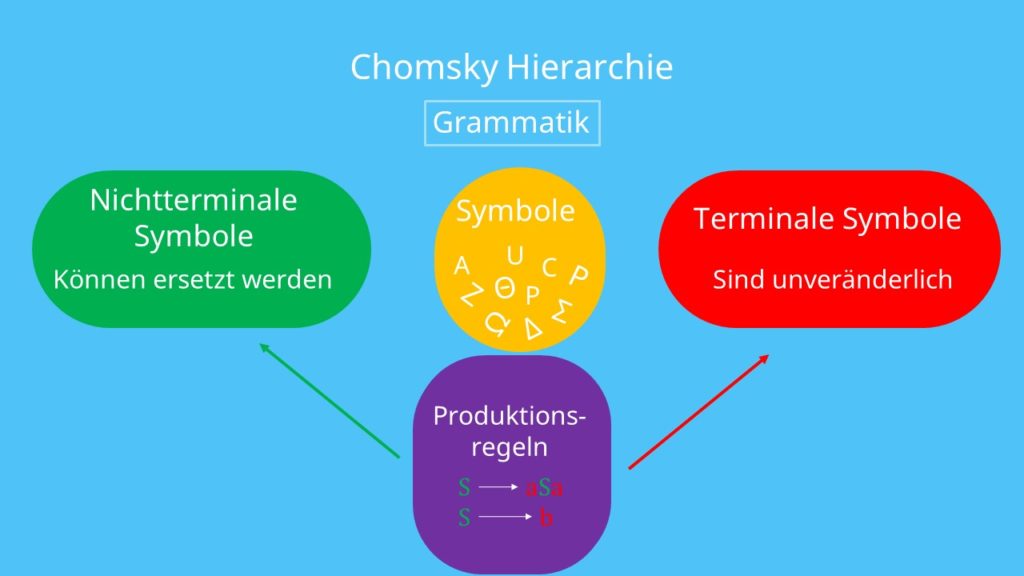
Nichtterminale Symbole können durch andere Symbole ersetzt werden, während terminale Symbole unveränderlich sind. Das heißt, man erkennt die Symbole an sogenannten Produktionsregeln. Diese Regeln beschreiben, aus welchen Zeichen welche anderen Zeichen entstehen können.
Formale Grammatiken beschreiben und erzeugen durch Symbole und Regeln formale Sprachen. Die Regeln definieren dabei, wie neue Symbole aus bereits bestehenden entstehen können. Bei den Symbolen unterscheidet man zwischen terminalen und nichtterminalen:
Man unterscheidet Grammatiken anhand der möglichen Einschränkungen ihrer Produktionsregeln. Die sogenannte Chomsky-Hierarchie stellt eine Hierarchie von Klassen formaler Grammatiken dar, welche formale Sprachen erzeugen. Darin werden vier verschiedene Arten von Typ-0 bis Typ-3 unterschieden, wobei Typ-0 die Sprache überhaupt nicht einschränkt, während Typ-3 die Grammatik sehr stark einschränkt.
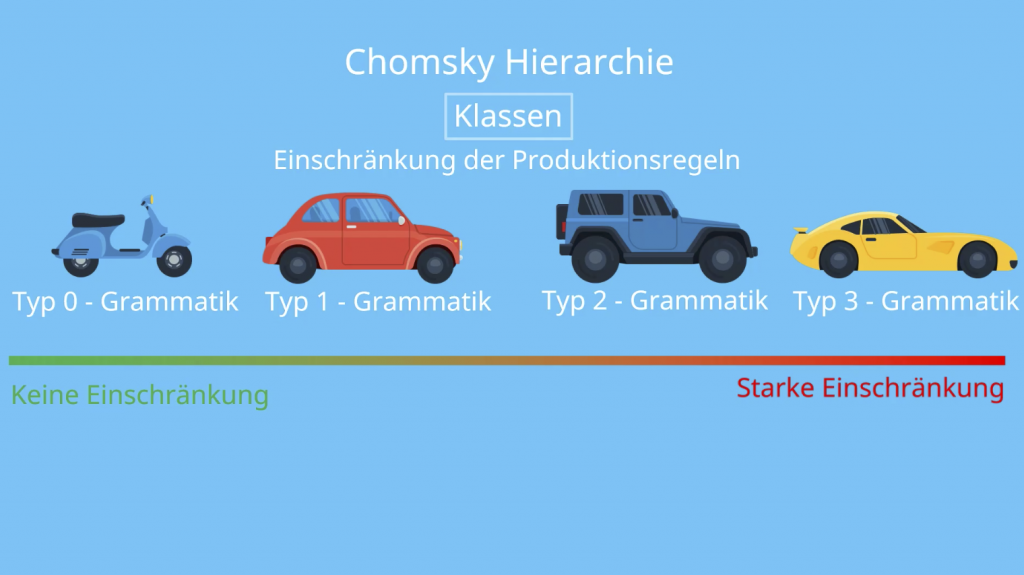
Die Typ-0-Grammatik wird auch Chomsky-Grammatik oder Phasenstrukturgrammatik genannt. Allgemein kann man sagen, dass alle formalen Grammatiken mindestens vom Typ-0 sind, da hier keine Einschränkungen gestellt werden. Es kann also aus jedem Wort ein beliebiges anderes Wort entstehen.
Typ-1-Grammatiken, auch kontextsensitive Grammatiken genannt. Sie erweitern die Typ-0-Grammatik um eine Längenbeschränkung. Diese Beschränkung sagt aus, dass bei einer Produktionsregel 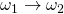 immer gelten muss, dass die Länge von
immer gelten muss, dass die Länge von 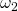 mindestens der Länge von
mindestens der Länge von 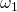 entspricht. Es gibt eine einzige Ausnahme: aus einem Symbol S darf das leere Wort
entspricht. Es gibt eine einzige Ausnahme: aus einem Symbol S darf das leere Wort  gebildet werden.
gebildet werden.
Typ-2 Grammatiken (kontextfreie Grammatiken), sind zusätzlich dadurch eingeschränkt, dass jede Regel der Grammatik auf der linken Seite genau ein nichtterminales Symbol, und auf der rechten Seite eine beliebige Kombination aus terminalen und nichtterminalen Symbolen enthalten muss. Die Kombination muss hierbei immer mindestens ein Element enthalten.
Typ-3-Grammatiken, auch reguläre Grammatiken genannt. Sie sind im Vergleich zu Typ-2-Grammatiken zusätzlich dadurch eingeschränkt, dass auf der rechten Seite der Produktionsregeln genau ein Terminalsymbol sein muss und optional ein Nichtterminalsymbol sein kann. Je nachdem, auf welcher Seite des Terminalsymbols das nichtterminale Symbol ist, spricht man von einer linksregulären oder einer rechtsregulären Grammatik. Typ-3-Grammatiken erzeugen die regulären Sprachen und werden von Endlichen Automaten erkannt.
Reguläre Grammatiken und Endliche Automaten
Die Reguläre Grammatik stellt eine Typ 3 Grammatik der Chomsky-Hierarchie dar und erzeugt reguläre Sprachen. Es ist ein 4-Tupel, bestehend aus der Menge der Terminalsymbole, der Nichtterminale und der Produktionen, sowie einem Startsymbol.
Die Grammatik wird über dieses 4-Tupel erzeugt:

N ist dabei die Menge der Nichtterminale oder auch Variablen und wird mit Großbuchstaben bezeichnet.

T ist die Menge der Terminalsymbole in Kleinbuchstaben.

S ist das Startsymbol und als Variable in N enthalten. P ist schließlich die Menge der Produktionsregeln.
Die Definition beschreibt somit zum einen die Grundelemente der Sprache, also Terminalsymbole, die beispielsweise bei Programmiersprachen für Schlüsselworte stehen. Aus diesen können dann Sätze zusammengestellt werden, die auf Produktionsregeln, bzw. Konstruktionsregeln basieren.
Beispiel
Reguläre Grammatiken erzeugen reguläre Sprachen, deshalb gibt es für jede reguläre Sprache immer mindestens eine reguläre Grammatik. Zur besseren Verständlichkeit betrachten wir die folgende Sprache als „Reguläre Grammatik Beispiel“:
![\[L = \{0^n1^{2m}|n>0, m\ge0 \}\]](https://davincii.de/wp-content/ql-cache/quicklatex.com-04f60d33fa17a66a95e469d231f43533_l3.png "Rendered by QuickLaTeX.com")
Sie enthält alle Wörter, die mit einem bis n Nullen beginnen und mit keiner oder einer geraden Anzahl Einsen enden. Wenn man diese Sprache auf eine wie eben beschriebene reguläre Grammatik zurückführen kann, dann ist sie regulär.
Gestartet wird mit dem Startsymbol S. Dabei wird versucht zunächst das kleinstmögliche Wort zu bilden. Das wäre einfach Null.
Mit der ersten Produktionsregel „S wird umgewandelt in Null“ bekommt man genau dieses Wort.

Man benötigt aber eine Möglichkeit mehr als eine 0 zu erzeugen. Das gelingt, indem an die Null einfach erneut das Startsymbol angefügt wird:

Nachdem eine Null erzeugt wird, befindet man sich wieder in S und kann dadurch so viele beliebige Nullen erschaffen. Im nächsten Schritt muss man das Wort entweder beenden oder mit den Einsen anfangen. Dabei kann man die Produktionsregel einfach erweitern:

S wird umgewandelt in Null S oder 1 S oder Epsilon.
Doch Vorsicht! Mit dieser Regel kann man das leere Wort 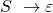 erzeugen. Oder eines, das direkt mit einer 1 beginnt:
erzeugen. Oder eines, das direkt mit einer 1 beginnt: 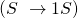 . Beides darf in dieser Sprache aber nicht passieren. Deshalb muss zwischen dem Teil des Wortes, das Nullen enthält und dem Rest unterschieden werden. Dafür braucht man eine weitere Variable.
. Beides darf in dieser Sprache aber nicht passieren. Deshalb muss zwischen dem Teil des Wortes, das Nullen enthält und dem Rest unterschieden werden. Dafür braucht man eine weitere Variable.

Mit dieser Regel können viele Nullen erschafft werden, dabei muss aber mindestens eine erzeugt werden, bevor man sich dem nächsten Teil des Wortes in B widmen kann. Von B aus beendet man entweder mit Epsilon oder erzeugt Einsen.

Wenn das Wort Einsen besitzt, müssen diese in gerader Anzahl vorhanden sein. Dies wird mit einer Schleife erreicht:


Dabei gelangt man von B mit einer 1 nach C und von dort mit einer weiteren 1 nach B zurück. Die Produktionsregeln erzeugen nun die beschriebene Sprache.
Endliche Automaten
Grundsätzlich gibt es für jede reguläre Grammatik einen zugehörigen deterministischen Automaten. Dieser wird durch einen nichtdeterministischen endlichen Automaten erstellt, indem aus den Nichtterminalsymbolen ein Zustand erstellt wird und zusätzlich aus jeder Konstruktionsregel einen Übergang erzeugt.
Im Gegenzug gibt es natürlich auch in jedem deterministischem endlichen Automaten eine reguläre Grammatik. Allgemein gilt: Jede Sprache, die endliche Automaten akzeptieren, wird von einer regulären Grammatik erzeugt.
Deterministische endliche Automaten (DEA)
Deterministische endliche Automaten – kurz DEA (Informatik) oder DFA (Englisch: deterministic finite state machine)– sind endlichen Automaten . Gibt man nun eine Eingabe, wobei nur Zeichen enthalten sein können, die im Eingabealphabet stehen, in den Automaten ein, dann passiert für jede Eingabe ein Zustandsübergang. Hierbei gilt, dass ein determinisitischer endlicher Automat immer eindeutig ist, bei welcher Eingabe welcher Zustandsübergang ausgeführt wird.
Die Arbeitsweise eines DEA ist hierbei so simpel wie genial: Nehmen wir an, es liegt ein Eingabewort vor, das nur aus Zeichen des Eingabealphabets besteht. Der Automat startet nun in seinem Startzustand, den wir hier  nennen. Nun liest der Automat das erste Zeichen des Wortes ein, wodurch sich der Zustand des Automaten ändert. Dafür brauchen wir die Übergangsfunktion: Der Automat betrachtet den aktuellen Zustand und das eingelesene Zeichen. Er erfährt durch die Übergangsfunktion den neuen Zustand, beziehungsweise den Folgezustand. Dies geschieht so lange, bis das Wort vollständig eingelesen ist. Befindet sich der Automat nun in einem Endzustand, dann wird das Eingabewort akzeptiert. Ist der Automat jedoch in einem normalen Zustand, wird das Wort verworfen.
nennen. Nun liest der Automat das erste Zeichen des Wortes ein, wodurch sich der Zustand des Automaten ändert. Dafür brauchen wir die Übergangsfunktion: Der Automat betrachtet den aktuellen Zustand und das eingelesene Zeichen. Er erfährt durch die Übergangsfunktion den neuen Zustand, beziehungsweise den Folgezustand. Dies geschieht so lange, bis das Wort vollständig eingelesen ist. Befindet sich der Automat nun in einem Endzustand, dann wird das Eingabewort akzeptiert. Ist der Automat jedoch in einem normalen Zustand, wird das Wort verworfen.
Beispiel-Anwendung
Als Beispiel soll ein Automat entwickelt werden, mit dessen Hilfe Telefon-Nummern erkannt werden sollen. Da es sich um ein einfaches Beispiel handeln soll, wird hierbei auf das erkennen internationaler Nummern verzichtet. Korrekte Telefon-Nummern sollen von folgendem Aufbau sein:
Die Nummer beginnt mit einer „0“ gefolgt von beliebiger Ziffer aus der Folge 1..9 , der dann wieder Ziffern aus 0…9 folgen können. Anschliessend folgt ein „/“ gefolgt von einer beliebigen Ziffer 1..9 der dann beliebig viele Ziffern von 0 …9 folgen dürfen.
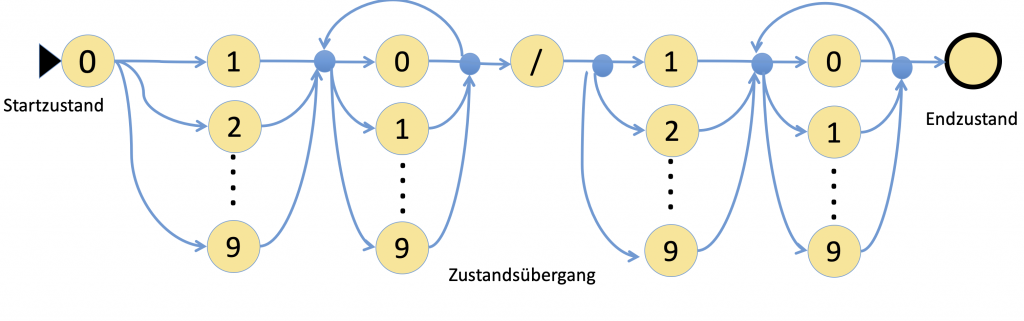
Ein entsorgender endlicher Automat hat dann folgende Gestalt:
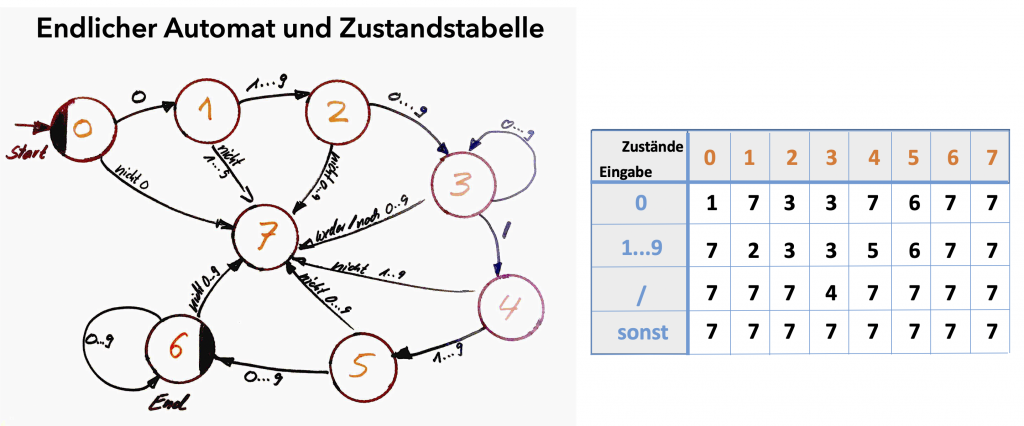
Ein wesentlicher Vorgang von EA ist das man diese sehr effizient in Programmcode überführen kann. Im folgenden ist das am Beispiel der Telefon-Nummern Erkennung dargestellt:
